Inspire 9 was bursting for the first Data Science Melbourne MeetUp which shows how much interest in the field there is amongst the community. The group was hosted by Phil Brierley from Pulse Data Science and Tiberius Data Mining.
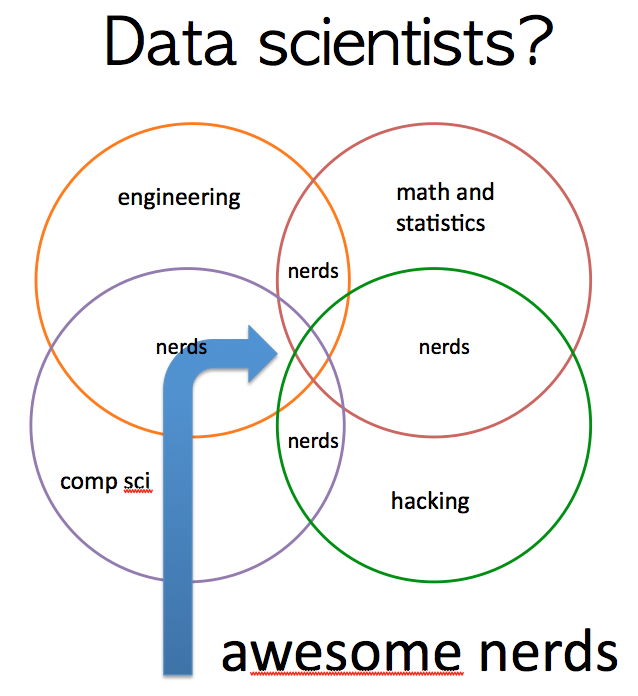
Delegates had already been asked ‘what is data science?’ through MeetUp before attending so the session was started with some brain storming. So, statistics, machine learning, data visualisation, data mining were some of the words that came up, albeit members were prompted for answers by the question, i.e. what does data science mean to you? e.g. machine learning, statistics, data visualisation, data warehousing, data mining etc. and the results showed that ‘etc.’ even had a frequency (I think that could have included me!). Data Science was best summarised by the following Venn Diagram used by Bitly’s Hilary Mason which shows the crossover of skills needed to be the most awesome nerd, or data scientist.
Phil then humorously broke down all the data of people joining the group over time from MeetUp stats before talking about how they came up with an attendance algorithm for the group to work out how many people were going to show up. Quite difficult when you don’t have any historical data, being the first event, so lucky Phil was able to call on a few domain experts, asking organisers of other groups their attendance conversion with the advice to take a bit off if it’s raining. Then the pizza algorithm to assess how much pizza should be bought which looks at how many people are male, how many are female and how many are students! So the first sample of data for Data Science Melbourne is the most important to be able to predict attendance, pizza consumption and so on for future events and entirely relevant to data science and the group, the first step of machine learning.
Jeremy Howard
Jeremy Howard is originally from Melbourne but spends most of his time in Silicon Valley where most of the world’s data driven start ups are located, off the back of two successful start ups of his own after pitching to SF Venture Capitalists and securing $11m, an amount that dictates that VCs generally want you in kicking distance. After selling the second of his start ups, Howard attended an R MeetUp group where he was introduced to Kaggle competitions for predictive modelling which he says whilst cool, it was a terrifying prospect as having ran his own business for ten years, people could have possibly found out that he was no good at what he was talking about.
It turned out that Howard won two out of the first three competitions that he entered and by the time he returned to the R MeetUp group, he was top of the world rankings for Kaggle competitions despite his lack of technical training and gave a ‘brain dump’ on how he does what he does, part of which was Random Forests, a class of machine learning algorithms which has been around since 1999 which Howard used to win competitions. After this session various start ups used the Random Forest Algorithm commercially as well as people using it for Kaggle competitions. Howard later became the first angel investor for Kaggle and nowadays spends his time as Data Strategist for Khosla Ventures, is also a Research Scientist and the University of San Francisco, Faculty at Singularity University, Mountain View, California and is also a Young Global Leader at the World Economic Forum.
What Howard discovered with Kaggle is that a small number of people were using Random Forest or Deep Learning Algorithms with lots of brain storming as a team to win competitions again and again and allowing algorithms to do the filtering and now Howard is planning the launch of a new start up focussed on building the software that puts algorithms and processes in place and makes them available to everyone regardless of statistical or coding knowledge.
To try and keep post length in check, I’ll be outlining the main content of Jeremy’s presentation in a separate post but it just remains to thank the organisers of the Data Science Melbourne group and wish the very best of luck in it’s success – an awesome start!


